
Einen Textbeitrag auf einer Website zu veröffentlichen ist simpel: einloggen, Text erfassen, speichern. Doch immer mehr Websites sind eine Art «Hub» für Daten verschiedener Art, die weit über das klassische Artikelprinzip hinausgehen. Viele davon sind zudem in Drittsystemen gespeichert und sollen von da einmalig oder regelmässig übernommen werden. In Backdrop CMS ein Fall für das Feeds-Modul, eine sehr flexible Lösung für den Datenimport.
Die Anwendungsfälle für Feeds sind zahlreicher als gedacht. Die typischen Eingabemasken eines CMS funktionieren zwar super, um Text und Bilder für einen Blogbeitrag einzupflegen. Bei tabellarischen Übersichten sieht es dagegen schon anders aus: Tabellendaten herumzuschieben, das geht in Excel oder Numbers einfach schneller. Auch die Bewirtschaftung von Händlerlisten kann über eine CMS-Oberfläche recht mühselig sein. Einfacher in solchen Fällen: erst offline bearbeiten, und dann per Datenimport ins CMS.
Inhalte importieren zum Projektbeginn…
Als Sitebuilder nutze ich den Import schon gleich bei Aufsetzen neuer Sites. Die meisten meiner Kundenprojekte haben ein gutes Dutzend weitgehend identischer Inhalte: Datenschutz, Impressum, personalisierte 404-Seite, Dankesseite für Formulareingaben. Diese Inhalte pflege ich in einer Art Mastersite und importiere sie zum Projektbeginn auf der neuen Site. Mit Tokens lassen sich sogar Variablen setzen oder der Firmenname dynamisch einfügen.
...und im Projektverlauf
Weit umfangreicher sind die Importe natürlich bei kundenspezifischen Inhalten. Produktdaten lassen sich oft aus einer CRM-Lösung herausholen und erst in Backdrop CMS mit Marketingdaten anreichern. Nicht selten importiere ich auch Daten aus bestehenden CMS – inklusive Drupal 7 (wo ich sie mit Views Data Export auslese; das Modul Image URL formatter bietet Hilfe beim Bilderexport).
Ein weiteres Einsatzgebiet ist schliesslich die regelmässige Aktualisierung von Informationen im laufenden Betrieb. Die Händlerliste aus der Adressverwaltung wurde bereits erwähnt. Feeds kann nämlich nicht nur ab lokaler Datei, sondern auch über das HTTP-Protokoll Daten einlesen. Die Anwendungsmöglichkeiten sind auch hier fast grenzenlos: Blogbeiträge von Partnersites, Wetterdaten im XML-Format, regelmässig aktualisierte Produkt-Infos vom Lieferanten. Feeds unterstützt auch das offene RSS-Format. Ich selber verwende in meinen Projekten fast immer das CSV-Format.
Daten vor dem Einlesen modifizieren
Seit geraumer Zeit ist übrigens auch das Zusatzmodul Feeds Tamper auf Backdrop CMS verfügbar. Es erlaubt, jeden importierten Wert nach vorgegebenen Regeln zu ändern: Ersetzen von Komma durch Punkt, Anpassen von Dateipfaden bei Bildern, Löschen von Führungszeichen in Preisangaben (etwa 10000 statt 10’000). Auf Backdrop CMS habe ich Tamper bislang noch nicht ausprobiert, aber in Drupal bot das Modul sogar Support für Regular Expressions.
Das Importskript erstellen
Für einen reibungslosen Import müssen natürlich sauber strukturierte Daten vorliegen. Im CSV-Format etwa muss Zeile 1 die Namen der Variablen beinhalten und entweder die Separation der Felder nach Komma oder Semikolon unterstützen. Tipp: oft hilft der Umweg über Google Spreadsheets, das einen sauber arbeitenden CSV-Export bietet.
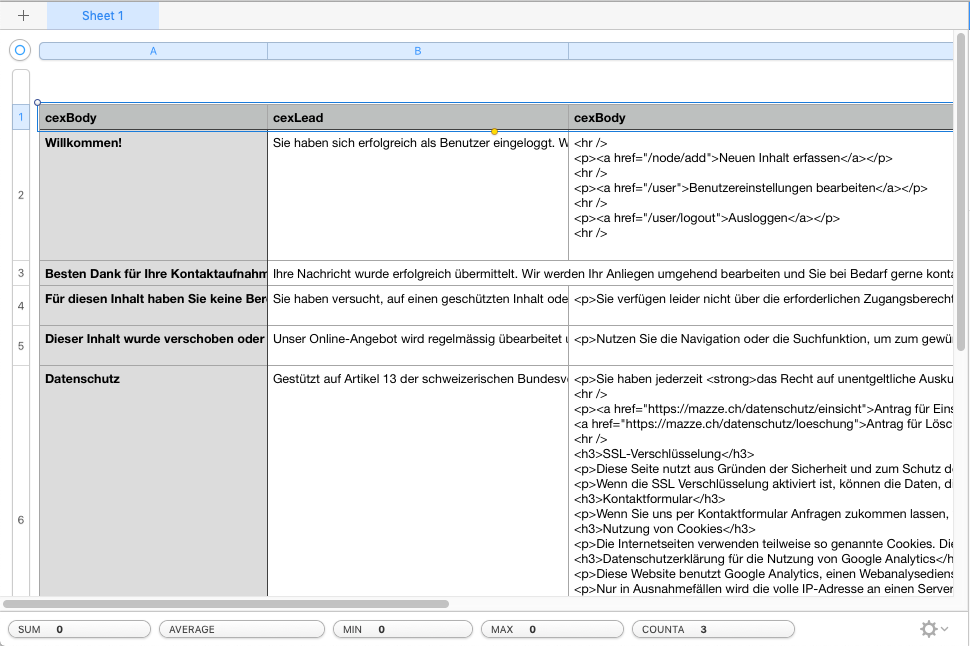
Anschliessend können wir das Importskript erstellen, in Backdrop CMS der «Feeds Importer» genannt (der spätere Import selber nennt sich dann «Feed»). Die gesamten Konfiguration lässt sich per Benutzeroberfläche vornehmen. Diese sieht auf den ersten Blick komplizierter aus, als sie wirklich ist, und die Hilfetexte erklären verständlich, was ein «Fetcher» oder ein «Processor» ist. Vereinfacht gesagt, klickt man sich einmal durch die Reiter auf der linken Seite.
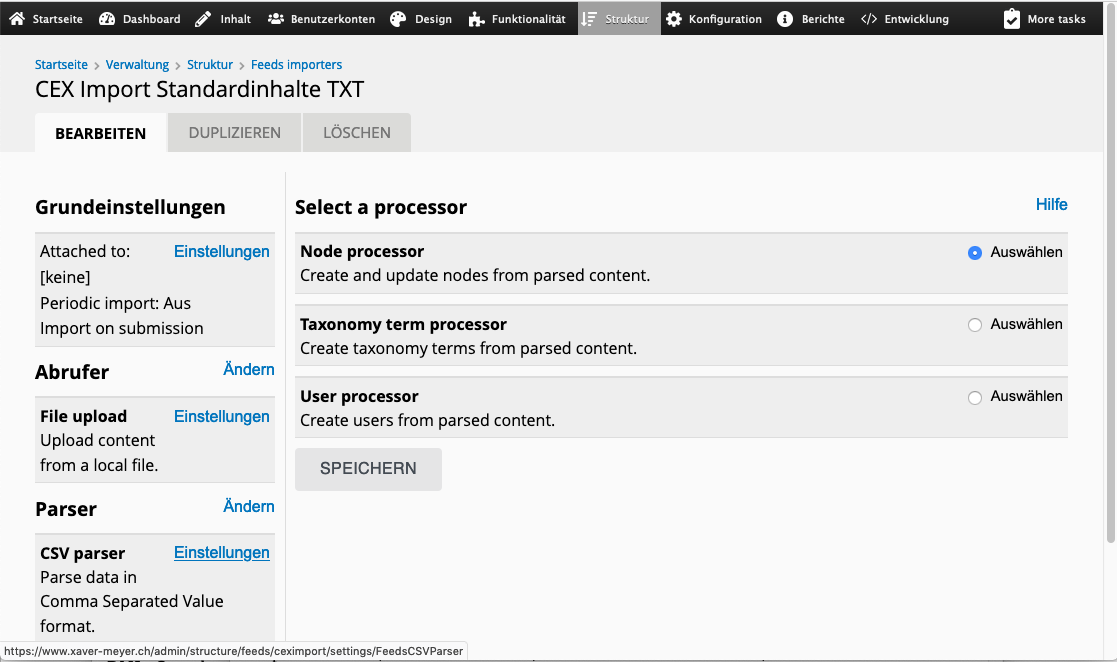
Bis auf den letzten Reiter geht es nur um Grundeinstellungen: Kommen die Daten aus einer lokalen Datei oder über das Netz? Was ist das Ausgangsformat? Und was soll der Feed erzeugen: Benutzer, Kategorien oder Inhaltsbeiträge?
Prozessoreinstellungen und Mapping
Der letzte Reiter «Prozessor» ist der wichtigste Bereich. Hier wird festgelegt, ob der Import regelmässig erfolgen soll (was eine eindeutige ID pro Eintrag in der Importdatei voraussetzt). Beim Modus liegt man mit «Update existing» fast immer richtig. Sehr wichtig auch bei regelmässigen Importen: Was passiert mit fehlenden Datensätzen (z.B. ein Produkt ist derzeit nicht verfügbar). Solche Einträge sollen zumeist nicht gelöscht, sondern nur deaktiviert werden, etwa da sie nach dem Import noch angereichert werden.
Im unteren Bereich lassen sich Autor und Lebensdauer des Inhalts bestimmen – für letztere Funktion fällt mir offen gesagt kein Szenario ein, aber gut zu wissen dass es möglich ist;-)
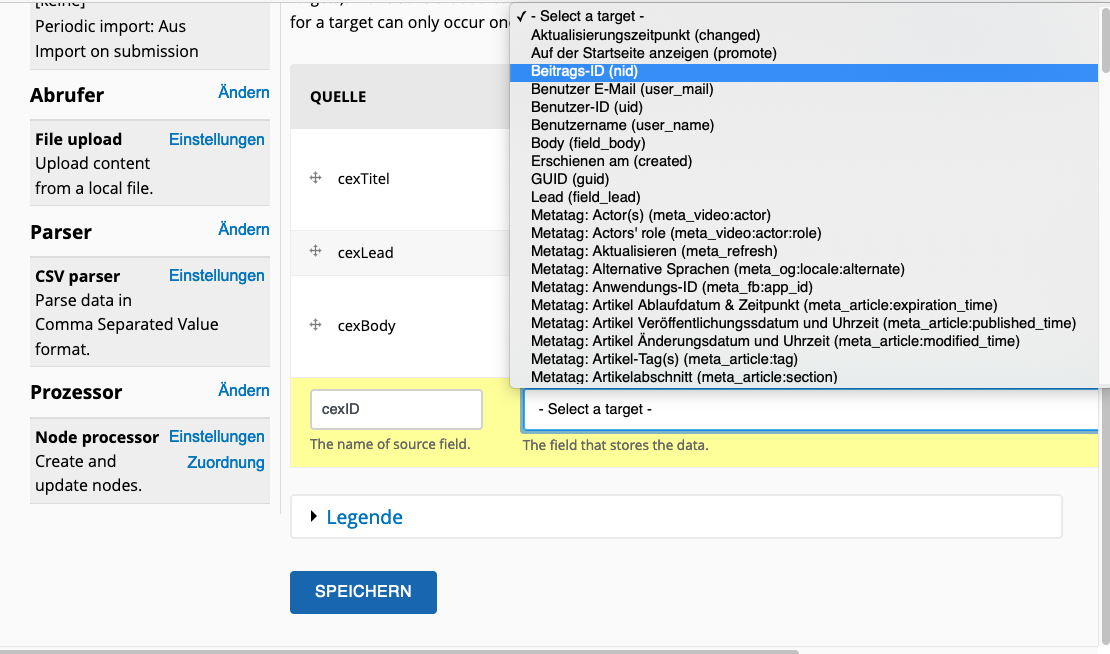
Im Unterbereich «Mapping» schliesslich werden die Header-Variablen aus der Importdatei den Feldern des Backdrop-Inhaltstyps zugeteilt. cexTitel (s. Abb. oben) befüllt das Titelfeld, cexLead wird ins Feld Leadtext importiert. Für Taxonomiefelder besteht die praktische Möglichkeit, bisher nicht vorhandene Werte automatisch anzulegen. Felder wie die Node-ID lassen sich zudem als «Unique» definieren und so als Key für wiederkehrende Importe nutzen.
Importieren und prüfen
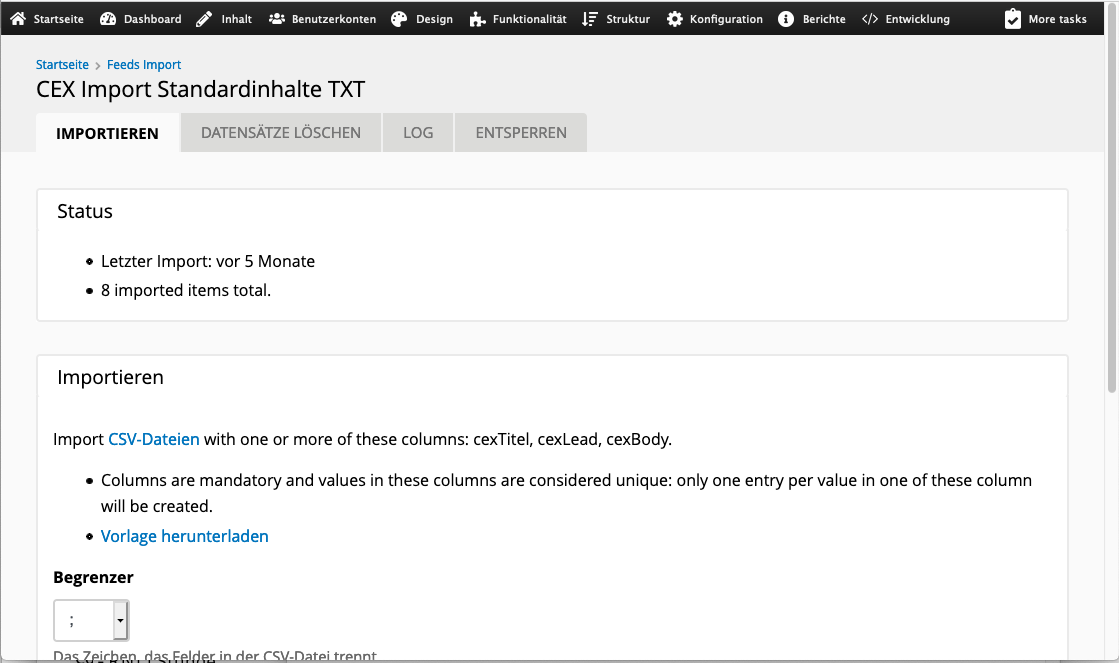
Für Neuanwender nicht zwingend ersichtlich: der Import wird über die URL www.meinedomain.ch/import angestoßen. Der Rest jedoch ist sehr einfach. Trennzeichen ist bereits ausgewählt, Importdatei laden, importieren und prüfen. Wichtig fürs Bugfixing: der jeweils letzte Import kann hier jederzeit rückgängig gemacht werden, auch Monate nach dem Import.
Das Feeds-Modul in Kürze
Feeds ist eine flexible, einfach zu bedienende Lösung für den Datenimport in Backdrop. Häufig nutze ich das Modul auch für die Übernahme von Daten aus alten Drupal-Sites, deren Datenmodell ich nicht zu 100% übernehmen möchte, da ich einen Neuaufbau der Architektur bevorzuge. Eine weitere Anwendung ist das Kuratieren von Inhalten aus anderen Plattformen, etwa die News einer Partner-Website.